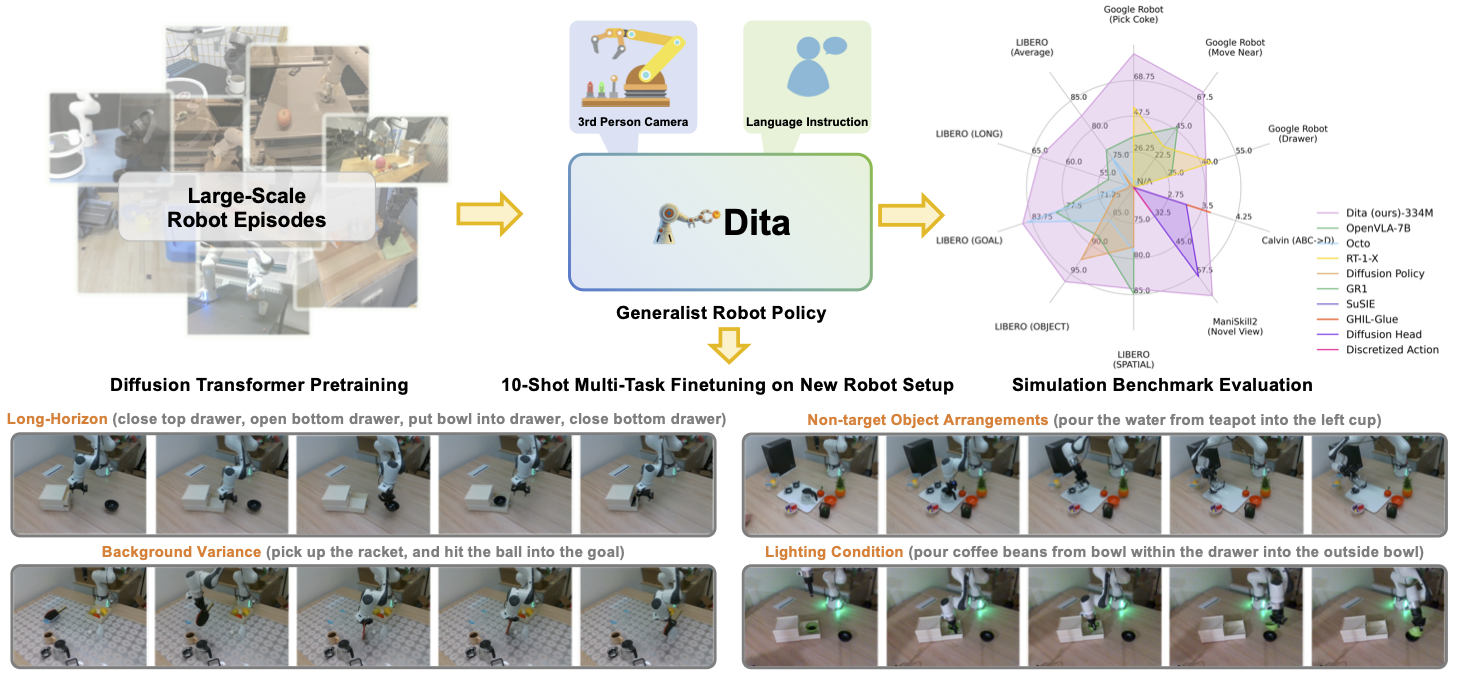
While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning---enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning.
Here, we illustrate the demonstration videos of our model. All experiments are 10-shot finetuning and the training samples are provided in the video above.
Here, we demonstrate the robust of the proposed model under SimplerEnv. We pretrain on OXE datasets and evaluate on SimplerEnv.
Here, we demonstrate the evaluation examples of the proposed model on LIBERO benchmark. We pretrain on OXE datasets and fintune on LIBERO.
@article{hou2025dita,
title={Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy},
author={Hou, Zhi and Zhang, Tianyi and Xiong, Yuwen and Duan, Haonan and Pu, Hengjun and Tong, Ronglei and Zhao, Chengyang and Zhu, Xizhou and Qiao, Yu and Dai, Jifeng and Chen, Yuntao},
journal={arXiv preprint arXiv:2503.19757},
year={2025}
}